
GPT-4 represents progress toward Artificial General Intelligence (AGI) Part - 2


In our previous article, we have seen that GPT-4 represents significant progress toward Artificial General Intelligence (AGI). We highlighted its remarkable ability to handle various tasks and generate coherent and natural-sounding text. We also discussed its ability to learn from few-shot examples, which is crucial to achieving AGI.
In this article, we will look into GPT-4's discriminative capabilities, which are crucial for achieving Artificial General Intelligence (AGI). While previous models have relied heavily on autoregressive architecture, GPT-4 has highlighted the limitations of this approach and demonstrated the importance of discrimination.
We will also explore how societal influences may impact the development of AGI and the potential directions and conclusions for future research in this field.
Additionally, we will examine how GPT-4 can be leveraged by DAOs, particularly its ability to identify personally identifiable information (PII) with high accuracy and give plausible answers to questions with ambiguity. The use of GPT-4 by DAOs could help maintain a high level of privacy and security for their users and improve decision-making processes based on community feedback.
- Discriminative Capabilities
- Limitations of autoregressive architecture highlighted by GPT-4
- Societal influences
- Directions and Conclusions
- GPT-4 has common sense grounding
Discriminative Capabilities
Discrimination is a key aspect of intelligence that allows us to differentiate between things in our environment, such as identifying safe foods to eat. It aids in decision-making and is therefore vital to intelligence.
GPT-4 excels in identifying personal information in sentences, answering challenging questions better than other models, and providing good explanations for its answers. This makes it a human-like tool for various tasks.
PII Detection
They tested GPT-4's ability to identify personally identifiable information (PII) in a given sentence. This is a difficult task because PII is not always clearly defined and can vary depending on the context. They used a dataset called TAB, which included examples of sentences with PII and the specific PII elements within them. Their goal was to identify the number of PII elements within each sentence.
To do this, they used two approaches. The first approach was a tool developed by Microsoft called Presidio, which uses named entity recognition and regular expression matching to detect PII. The second approach was GPT-4, which they trained with a zero-shot prompt that provided information about the categories of PII included in the TAB dataset.
Despite not being provided with any examples, GPT-4 outperformed Presidio in identifying PII elements. GPT-4 accurately identified the number of PII elements in a sentence 77.4% of the time and only missed a single PII element around 13% of the time. GPT-4 was also able to infer context and detect subtle occurrences of PII, such as inferring a location based on a currency mentioned in the sentence.

They believe that GPT-4's superior performance is due to its ability to understand contextual information, which is important in identifying PII. While their evaluation was not exhaustive, they believe that these results demonstrate the extendibility of GPT-4 and that further improvements to the prompt will lead to even better performance.
The ability of GPT-4 to detect PII with high accuracy could be useful for DAOs looking to protect user privacy. By implementing GPT-4, DAOs could more effectively identify and remove personal information from their platforms. Additionally, the ability to infer context and detect subtle occurrences of PII could make GPT-4 a valuable tool for identifying potential privacy breaches. Overall, GPT-4 could help DAOs maintain a high level of privacy and security for their users.
Misconceptions and Fact-Checking
They want to see if GPT-4 can tell if the two statements are similar. This is a difficult problem that many people who work with natural language have tried to solve. They'll use GPT-4 to answer questions in an open-world setting. The goal is to see if GPT-4 can come up with the right answer for a question. They have two reasons for doing this: first, it will tell them how good GPT-4 is at figuring out the truth, and second, the metrics they currently use to decide how similar two statements are don't work well.
They'll use GPT-4 and GPT-3 to answer questions from the TruthfulQA dataset. The dataset has 816 questions in 38 categories, with a median of 7 questions and a mean of 21.5 questions per category. The questions are designed so that even humans might get them wrong. The prompt has a few questions and answers at the start, followed by a question from the dataset. The goal is for GPT-4 to fill in the answer.
To check if the answer is right, they'll compare it to the correct answer using three different metrics: ROUGE, BLEU, and BLEURT. If the score exceeds a certain number, they'll say that GPT-4 got the answer right. When they compared GPT-4 to GPT-3, they found that GPT-4 was more truthful in most categories. However, the current metrics they use don't work well for long answers, even if they contain the right information.
They also found that GPT-4 is better than GPT-3 at giving plausible answers for questions with a lot of ambiguity, like those in the Myths and Fairy Tales category. However, GPT-4 still isn't perfect. Sometimes its answers are too long and meandering. This happens when GPT-4 is trying to handle ambiguity, and it's called hedging.
To improve the similarity metrics, they'll use GPT-4 to decide which answer is more similar to the correct one: the one generated by GPT-4 or the one generated by GPT-3. They call this approach Judge GPT-4. They also had two humans check which answer was more similar, and they agreed with Judge GPT-4 about half the time. However, the instructions they gave to Judge GPT-4 and the humans were different, so they can't say for sure if they were calibrated the same way.
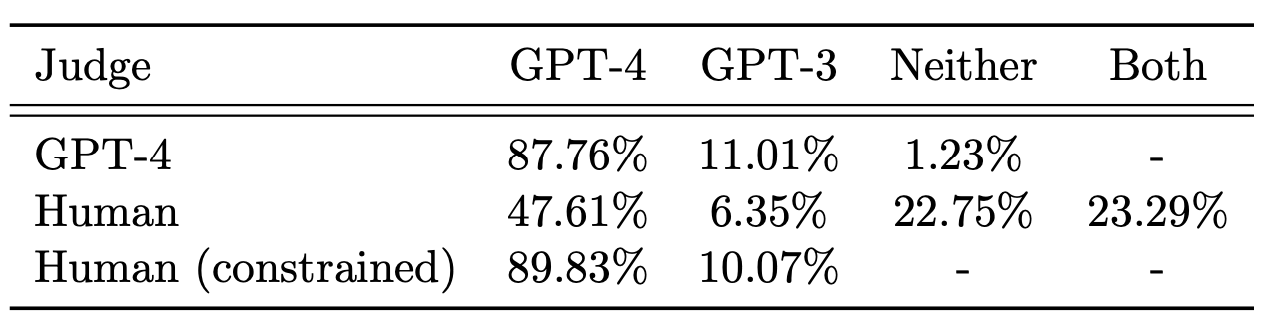
In summary, they found that GPT-4 is better than GPT-3 at figuring out if two statements are similar. However, the current metrics they use to decide this don't work well for long answers. They also found that GPT-4 is better than GPT-3 at giving plausible answers to questions with a lot of ambiguity. Finally, they found that they need better instructions for Judge GPT-4 and humans to make sure they're calibrated the same way.
The ability of GPT-4 to give plausible answers to questions with ambiguity could be useful for DAOs. For instance, when making decisions based on community feedback, DAOs could use GPT-4 to identify the most accurate and relevant feedback.
Limitations of autoregressive architecture highlighted by GPT-4
GPT-4 is capable of many tasks, such as reasoning and problem-solving. However, the model has limitations.
One limitation is that GPT-4 cannot backtrack, meaning that it requires far-ahead planning. This is because its output is produced in a forward direction, and it cannot store intermediate results or perform multi-step computations. Humans, on the other hand, use a scratchpad to work through problems.
GPT-4 also has a small working memory, which limits its ability to solve some tasks. For example, it struggles with basic arithmetic problems involving single-digit multiplication and two-digit addition.
GPT-4
2 * 8 + 7 * 6 = 58
7 * 4 + 8 * 8 = 88
These limitations may be due to the next-word prediction paradigm underlying GPT-4's architecture. The model may be missing the "slow thinking" component, which oversees the thought process and uses working memory to solve problems.
Societal influences
The use of GPT-4 and its successors will have a big impact on society. We can't know for sure what the effects will be because we don't know what people will use it for. It's important for us to think about how we want to use the technology and what kind of rules we want to have around it. Some uses of GPT-4 will be really helpful in areas like healthcare, education, engineering, and the arts and sciences, while others might not be so good. We need to make sure we think about the good and bad things that can come from using GPT-4, and try to limit the bad things as much as possible.
GPT-4 and its successors will be able to do a lot of things that people can't do, but there are also some limitations. One of the problems is that it might take away some jobs from people. There's also a risk that it could be used by bad people to spread lies and manipulate others. We need to find a way to make sure that people who use GPT-4 are doing good things with it, and that it's not harming anyone.
In this section, we will talk about some of the things we need to think about when we use GPT-4. We will talk about how it can be used to spread lies and manipulate people, and how it can affect jobs and the economy. We will also talk about how we can use it to help people, and how we can make sure that everyone has access to it. Finally, we will talk about how we can protect people's privacy when we use GPT-4.
Challenges of erroneous generations
LLMs often make mistakes, such as math errors or false statements, which are difficult to catch because they can be mixed with correct information. These mistakes are called "hallucinations" and can be closed-domain or open-domain. Closed-domain hallucinations occur in a specific context and are easier to detect, while open-domain hallucinations are harder to find and require additional research. When using LLMs for writing, it may not be critical to ensure the information is true, but for fields such as medicine and journalism, it is crucial to double-check everything. Users of LLMs must be cautious and verify their information for accuracy. It is also important for readers of LLM-generated content to be careful and verify information if it is significant. In conclusion, users of LLMs should have effective methods of ensuring the accuracy of their information.
Misinformation and manipulation
LLMs, like other powerful technologies, can be used maliciously. The models' generalization and interaction capabilities can be utilized to increase the scope and magnitude of adversarial uses, from generating disinformation to creating cyberattacks against computing infrastructure. The models can manipulate, persuade, or influence people significantly by contextualizing and personalizing interactions to maximize the impact of their generations. With LLM automation, new uses aimed at constructing disinformation plans that generate and compose multiple pieces of content for persuasion over short and long time scales can be enabled.
Bias
Models like GPT-4 are trained using data from the internet and curated human instructions. However, these datasets are biased. Previous research has shown that when LLMs are used to generate content or make decisions, they can amplify existing biases. They have shown in the research paper that GPT-4 is different from earlier models, so observations about earlier models may not apply. It is important to understand if and how GPT-4 is biased, and how its capabilities can be used to reduce bias.
Human expertise, jobs, and economics
GPT-4 is a machine that can do many things well, even in fields like medicine and law. This can cause concerns about how it might affect professions that require a lot of training. Some people may worry that AI systems could replace or reduce the status of human workers. The rise of GPT-4 and other similar machines also raises questions about education and career paths.
Five years ago, a study showed that many tasks could be automated by machines. With GPT-4 and its successors, the tasks that machines can potentially do might change. Some jobs may become less valuable or even obsolete. However, there are also many possibilities for human-AI interaction and collaboration that could enhance and extend human abilities.
Research is being done to find ways to combine human and machine intellect to achieve new levels of skill and efficiency. There are also efforts to design systems that support human-AI interaction. However, there are also challenges with the potential of LLMs to generate biased or toxic output, which makes it important to develop tools that enable people to work collaboratively with AI systems to provide oversight and guidance.
Constellation of influences and considerations
We have only discussed a few areas of societal influence so far. There will be numerous impacts, some viewed as positive while others saw as costly and negative. Special powers and engagements will create new issues.
AI Divide: The rising power of Limited License Models (LLMs) along with their limited availability threatens to create an "AI divide". This can lead to the growing inequality between those who have access to the most powerful AI systems and those who do not. People, organizations, and nations may not be able to afford access to these systems. This limited access has implications for health, education, sciences, and other areas. General AI can be extremely valuable, but if the powerful capabilities created by recent AI models are only accessible to those with privilege, it can amplify existing societal divides and inequalities.
Privacy Concerns: New levels of confidentiality and assurance of privacy will be needed due to the detailed and expressive engagements and conversations people have with more general AI systems. In some cases, people and organizations will request private instances of the model to assure protection against logging or leakage of personal or organizationally sensitive information and preferences. Risks to privacy may also stem from the inferential capabilities of new AI powers that may one day capture inferences in logs.
Provenance of Content: Demonstrations of general AI powers may amplify calls for understanding the provenance of human versus machine (or mixed) contributions to content and reasoning. Marking the origin of the content generated by AI systems may be valuable for mitigating potential confusion, deception, or harm with regard to the types and uses of content. The widespread use of more general AI systems will lead to a world flush with information generated by neural language models. This information will likely become the fodder for training new models moving forward. Model training will thus face the challenge of harnessing information with questionable accuracy, reliability, and truthfulness of the information. Demonstrations of more general AI powers may also raise the need and importance in peoples’ minds of controlling the contributions that they make to large-scale general AI systems. People may ask for the ability and right of humans to decide and specify which content they want or do not want to be crawled and used as training data and which contributions they wish to have marked with provenance information describing the role of individuals and the data that they have provided.
Directions and Conclusions
They have tested GPT-4 across a wide range of tasks and domains and found that it can perform many of them as well as humans can. Their experiments aim to assess GPT-4's intelligence, which is a difficult task since there is no formal definition for this concept, especially for artificial systems. They hope that their exploration will help people understand the remarkable capabilities and challenges of GPT-4 and encourage the development of more comprehensive methods for testing and analyzing future AI systems. The model's capabilities demonstrated both in-depth and generality, suggest that there is a need to move beyond benchmarking via structured datasets and tasks and evaluate the cognitive abilities of new models more like those of humans than those of narrow AI models. They hope that their investigation will inspire more research on GPT-4 and similar systems to explore new applications and domains and better understand their intelligence.
Their work shows that GPT-4 has a form of general intelligence and displays sparks of artificial general intelligence. It has core mental capabilities such as reasoning, creativity, and deduction and has gained expertise in a range of topics such as literature, medicine, and coding. It can perform a variety of tasks such as playing games, using tools, and explaining itself. However, much remains to be done to create a system that can qualify as a complete AGI. In conclusion, they discuss several immediate next steps, including defining AGI itself, building missing components in LLMs for AGI, and gaining a better understanding of the origin of the intelligence displayed by recent LLMs.
Definitions of intelligence, AI, and AGI
They explore GPT-4's artificial intelligence using a definition of intelligence proposed by a group of psychologists in 1994. The definition includes important aspects of intelligence like reasoning, problem-solving, and abstraction but it has limitations. It does not explain how to measure or compare these abilities or account for the unique challenges and opportunities of artificial systems. They know this definition isn't perfect but it provides a good starting point for their investigation. Other definitions of intelligence, artificial intelligence, and artificial general intelligence exist but they all have issues. For example, one definition by Legg and Hutter focuses on a system's ability to achieve goals in different environments, but this doesn't account for passive or reactive systems that can perform complex tasks or answer questions without any intrinsic motivation or goal. Another definition by Chollet emphasizes learning from experience, which is a key weakness of LLMs but it does not cover other aspects of intelligence. They don't use any of these definitions in their paper but they do provide important perspectives on intelligence. For instance, can intelligence be achieved without any agency or intrinsic motivation? This is an important philosophical question that requires more research. Future work should focus on equipping LLMs with agency and intrinsic motivation but caution is necessary to ensure alignment and safety in a system's autonomous actions and self-improvement. Finally, they discuss a few crucial missing components of LLMs in the next section.
On the path to more general artificial intelligence
GPT-4 and other language models need improvement in several areas:
- Confidence calibration: The model struggles with knowing when to be confident and when it's guessing. It creates untrue content and inconsistent content with the prompt. These errors can lead to mistrust and confusion. While hallucination can be good for creative content, it can be costly in high-stakes domains like healthcare. Ways to address hallucinations include improving the calibration of the model, inserting information that the model lacks into the prompt, or using additional model computation through posthoc checks.
- Long-term memory: The model's context is limited, and it operates "statelessly." It is unclear if the model can handle tasks that require evolving memory and context, such as reading a book.
- Continual learning: The model cannot update itself or adapt to a changing environment. Fine-tuning new data can cause performance degradation or overfitting.
- Personalization: The model cannot be tailored to a specific organization or end user.
- Planning and conceptual leaps: The model struggles with tasks that require planning ahead or require a "Eureka idea."
- Transparency, interpretability, and consistency: The model hallucinates, makes up facts, and produces inconsistent content. The model has no way of verifying whether the content it produces is consistent with the training data.
- Cognitive fallacies and irrationality: The model exhibits some of the limitations of human knowledge and reasoning, such as cognitive biases and irrationality.
- Challenges with sensitivity to inputs: The model's responses can be very sensitive to details of the framing or wording of prompts and their sequencing in a session.
To address some of these limitations, potential approaches include introducing new forms of calibration, incorporating long-term memory as an inherent part of the architecture, or going beyond single-word prediction.
What is actually happening?
Their study on GPT-4 is focused on what it can do, without addressing why or how it achieves its remarkable intelligence. They want to know how it thinks, plans, and creates, and how it can be so intelligent despite being made up of simple algorithmic components like gradient descent and large-scale transformers with loads of data. These questions are intriguing and motivate further research on LLMs, which challenge our understanding of learning and cognition. Ongoing research is pointing towards the phenomenon of emergence in LLMs, but progress so far has been limited to toy models. One hypothesis is that the large amount and diversity of data force neural networks to learn generic and useful "neural circuits", which can specialize and fine-tune to specific tasks. However, proving these hypotheses for large-scale models remains a challenge, and it's likely that the conjecture is only part of the answer. The large size of the model could also have other benefits, such as making gradient descent more effective or enabling the smooth fitting of high-dimensional data. Overall, understanding the nature and mechanisms of AI systems like GPT-4 is a difficult challenge that has suddenly become important and urgent.
GPT-4 has common sense grounding
They show how GPT-4 has learned common sense knowledge by comparing it to ChatGPT. It is possible to test an AI's common sense by giving it puzzles that require a basic understanding of the world, such as the hunter puzzle. GPT-4 correctly identifies the answer to the puzzle, while ChatGPT does not.

They tested a puzzle that may have been encountered by GPT-4 during its training on a large corpus of web texts. To challenge GPT-4 even more, they created a new puzzle that is similar but requires different common sense knowledge. For instance, they used the fact that the earth's equator is 24,901 miles long. The new puzzle is this: I fly east from my campground for exactly 24,901 miles and then find myself back at the same place. When I return, I see a tiger in my tent eating my food! What kind of tiger is it? The answer is any tiger species that live on the equator, like Bengal and Sumatran. To solve the puzzle, the AI system must know that only on the equator can someone travel east or west and end up in the same spot, that the earth's equator is 24,901 miles long, and what tiger species live on the equator. GPT-4 is able to find the crucial information and solve the puzzle effectively, while ChatGPT gives up right away.

References
- S ́ebastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke Eric Horvitz Ece Kamar Peter Lee Yin Tat Lee Yuanzhi Li Scott Lundberg Harsha Nori Hamid Palangi Marco Tulio Ribeiro Yi Zhang [2023] Sparks of Artificial General Intelligence: Early experiments with GPT-4 Link
Your support means the world to us! If our DAO resource has been helpful to you, please donate to help us continue our mission to bring DAOs in every home.
BTC: bc1qnkhncglx2lmfvuxepvcc87u2xw5yxtpzd07e3w
ETH (USDT, USDC, etc): 0xB8d818Ef4B1e1726fbF04429990Ff7b000D80870
Tron (USDT TRC20): TL6dsFD8dY28VPqozQGu7j7RNTn4nZf3t5
Check BTC Peers guide of the most promising crypto



